

AKS Spot Nodes Harm Nearby Workloads
Why adding Spot nodes to your Azure Kubernetes Service (AKS) cluster will cause user-facing timeouts, even if your services don’t run on them. And what you can do to fix it.

Written by Wenpin Cui, Shao Liu, and Alex Filipchik, members of the engineering teams that work on infrastructure.
For months, small spikes of unexplained 520/524 errors sat quietly on our dashboards, less than 0.03% max, easily ignored. Nobody complained, so the Infrastructure team put it in the we-will-get-it-done-eventually (read never) bucket. However, even minor issues can signal deeper problems. When one of these elusive errors unexpectedly disrupted a key customer experience, it quickly escalated from a rare anomaly to a critical infrastructure investigation, leading to very intriguing discoveries.
Chasing Ghosts in the Infrastructure

Once we knew that those disruptions were indeed a real problem, we jumped straight to our logs, expecting clear answers. At Cloudkitchens, we run most of our web applications on Azure AKS, fronted by Cloudflare (fairly solid stack) and a very simple proxy (Ingress Gateway), as illustrated by the above diagram, so our first instinct was to look for possible issues in either product stack (bugs) or our own infrastructure. Surprisingly, we found nothing suspicious (like missing health checks or improper shutdown sequences). The next suspect was our service mesh. We inspected all the logs and metrics we collected, but found nothing suspicious.
We realized we needed deeper instrumentation, so we started capturing Ray IDs, a special trace request header that Cloudflare can supply. The next time the errors hit, we’d have the fingerprint, which we can trace through all the layers.
When the next spike came, we caught it immediately, only to find something even stranger. The Ray IDs for these failed requests were still missing from every log inside our cluster. They weren’t just failing; they never even made it into Kubernetes.
The mystery deepened: our infrastructure seemed innocent. Was the problem actually upstream, somewhere in Azure’s managed load balancing?
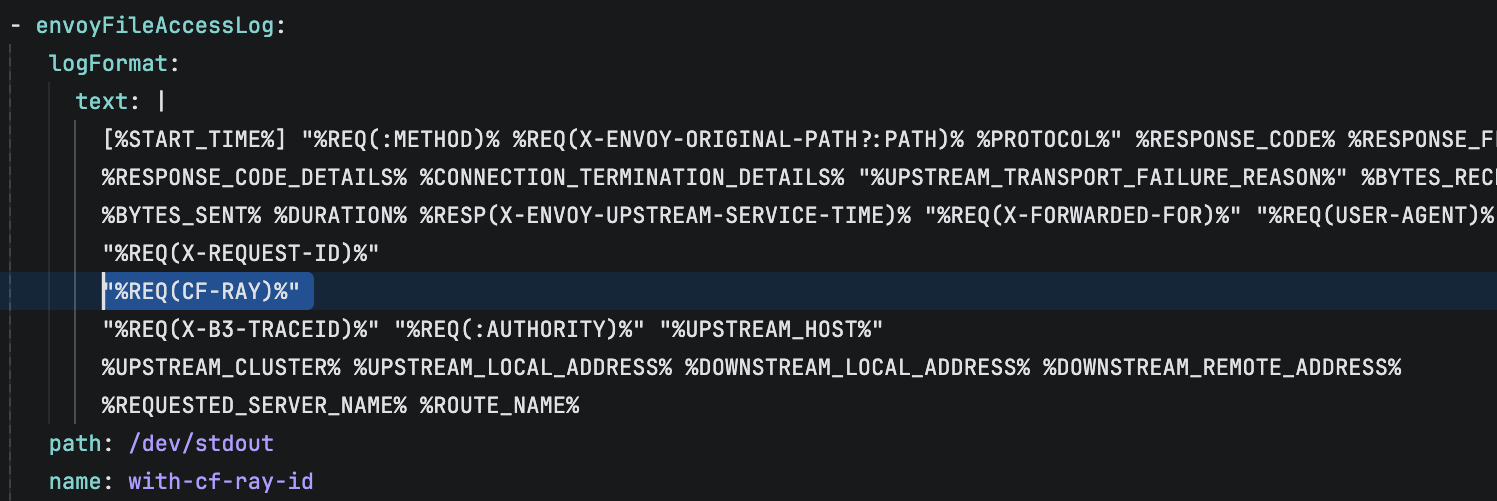
Ray ID: How to
If you are wondering how to capture Ray IDs yourself (assuming you are using Istio as well), here is the configuration example:

Diving Deep Into Azure AKS Internals
At this point, we knew the packets were disappearing somewhere upstream, but where? We had to figure out exactly how Azure’s Load Balancer interacts with AKS services. Initially, we assumed that the Azure Load Balancer picked a healthy pod to route requests to, perhaps randomly or in round-robin fashion. It seemed logical enough, but as it turned out, it wasn't how it worked at all.
Confused? We were, too. So we dug deeper and realized Azure Load Balancer doesn't route directly to pods. In fact, Azure Load Balancer has no knowledge of Kubernetes pods, nor does it know which node hosts which pod or which pod belongs to which service.
In reality, each AKS cluster automatically receives two Azure Load Balancers: one for external and one for internal traffic. Every time we create a Kubernetes Service with type Load Balancer, it is mapped to an external Azure LB, which comprises several key components:
Frontend IP: The public IP address for ingress traffic. Each frontend IP maps to a Kubernetes LoadBalancer service.
Backend pool: The group of VMs or Virtual Machine Scale Set instances serving requests. AKS creates a backend pool containing all Kubernetes nodes. Crucially, Azure Load Balancer doesn't route directly to pods. Instead, it routes traffic to nodes. Not just nodes running the service, but all nodes in the AKS cluster.
Load-balancing rules: Define how incoming traffic is distributed across backend pool instances. Each rule maps a frontend IP configuration and port to multiple backend IP addresses and ports.
Thus, every request makes two hops to reach our pods:
Azure LB → Node: Azure LB picks a random healthy node from the entire cluster.
Node → Pod: The node relies on IPtables rules configured by kube-proxy to forward traffic to one of the ready endpoints associated with the LoadBalancer service, which could be on a different node. IPtable internally also uses a conntrack module to maintain the mapping so at TCP level, the routing is consistent.

Here is a detailed example of the configuration in question:
Given a service that we want to expose externally:

A corresponding frontend IP configuration, matching the public IP found in .status.loadBalancer.ingress[0].ip of the Kubernetes service, can be located within the Azure Load Balancer.
Additionally, a load balancing rule is established to direct traffic from the frontend IP to the appropriate backend servers.

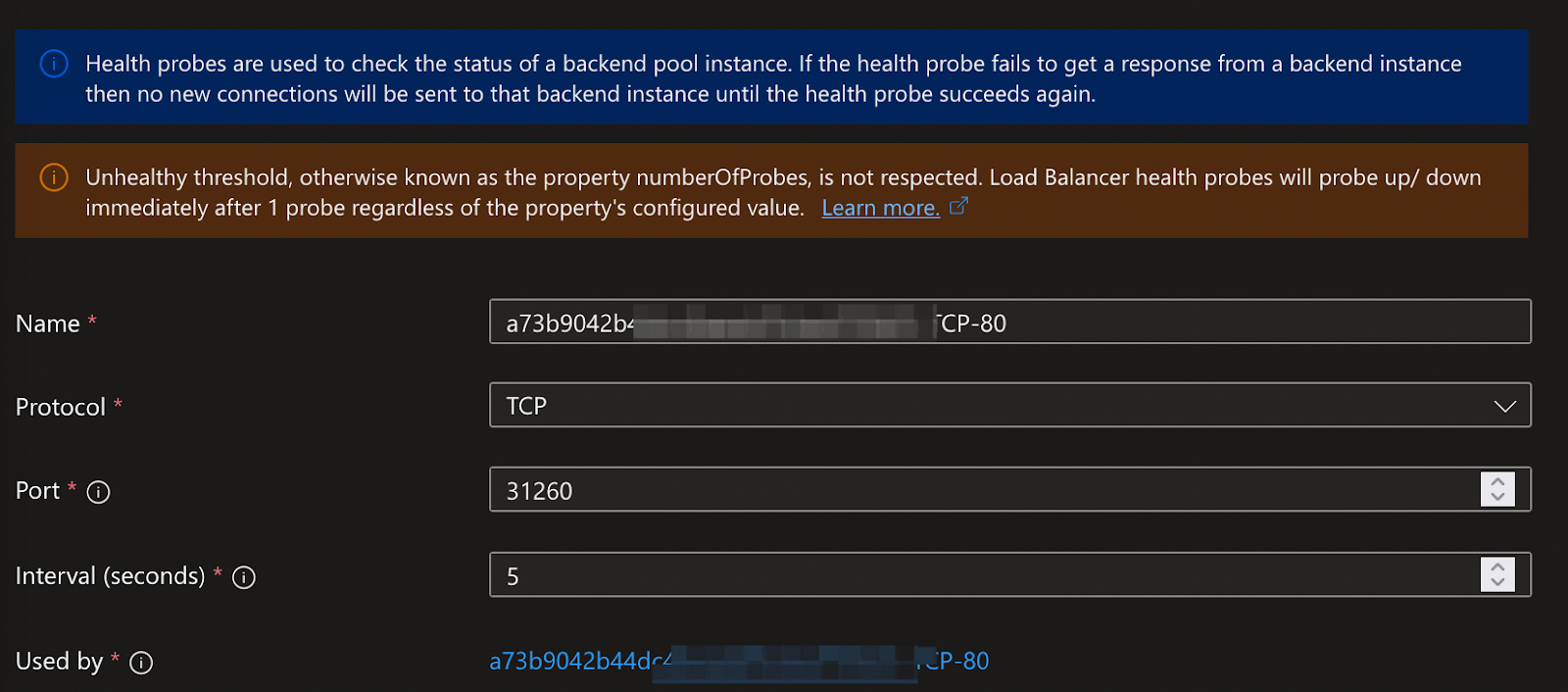
In the above example rule, you can see that Azure Load Balancer configures the frontend IP, backend pool, and a health probe. The Azure Load Balancer only directs traffic to healthy nodes. The health probe, configured in this rule, determines node health. In this example, by default, Azure checks for a successful TCP connection on port 31260 for each node in the cluster. This port is a NodePort, meaning it's open on all AKS cluster nodes, ensuring successful health probes for healthy nodes.
Why do requests vanish?
You might be asking: What actually happens when a Kubernetes node suddenly goes away?
The answer is simpler, and worse, than you might think: timeouts.
To understand why, let's look closely at Azure Load Balancer’s behavior. Azure determines node health through periodic health probes (TCP checks) every five seconds. If a node abruptly fails, such as during a spot node eviction, the Azure Load Balancer may still send traffic to it for several seconds, until the VM is eventually removed from the serving pool.

During that brief window, packets sent to these unhealthy nodes vanish silently, never reaching your pods. From our customers' perspective, this manifests as unexplained 520/524 errors from Cloudflare, depending on the exact TCP connection state when the node disappeared.
But why doesn't AKS handle this better? Ideally, nodes should gracefully terminate, actively closing connections and immediately signaling to Azure Load Balancer to stop routing traffic their way. Unfortunately, AKS doesn't currently handle node termination gracefully. We suspect flaws in this termination process prevent AKS from promptly deregistering nodes from the load balancer backend pool.
As a result, even healthy services running exclusively on stable nodes are vulnerable to intermittent errors caused by unrelated node failures, especially if Spot VMs are churning.
Mitigation: a workaround with trade-offs
With clarity on the root cause, the next logical step was to find a solution. We quickly realized that Azure’s Load Balancer doesn't allow us to explicitly exclude spot nodes, but Kubernetes itself provides an important configuration option: externalTrafficPolicy. This policy controls how incoming external traffic is distributed across Kubernetes nodes.
Default mode: Cluster
By default, Kubernetes sets the externalTrafficPolicy to Cluster. In this mode, the Azure Load Balancer forwards traffic evenly across all nodes in your AKS cluster, regardless of whether or not a given node hosts relevant pods.
This design aims to evenly spread load, but we've discovered a critical drawback: when unrelated nodes (such as spot instances) fail abruptly, Azure continues to route traffic to these failing nodes until their health checks fail, leading to intermittent packet drops and 520/524 errors.
Alternative: Local mode
The alternative is to set externalTrafficPolicy to Local. This option addresses the problem by instructing the Azure Load Balancer to forward traffic only to nodes that are actively running pods associated with the LoadBalancer service.
As explained clearly in Azure's official AKS documentation:
"With the Local traffic policy enabled, the load balancer health probes automatically detect which nodes are running the pod for a given service and only send traffic to those nodes."
This means spot nodes, or any other unrelated nodes, will never receive traffic meant for services not explicitly hosted on them.

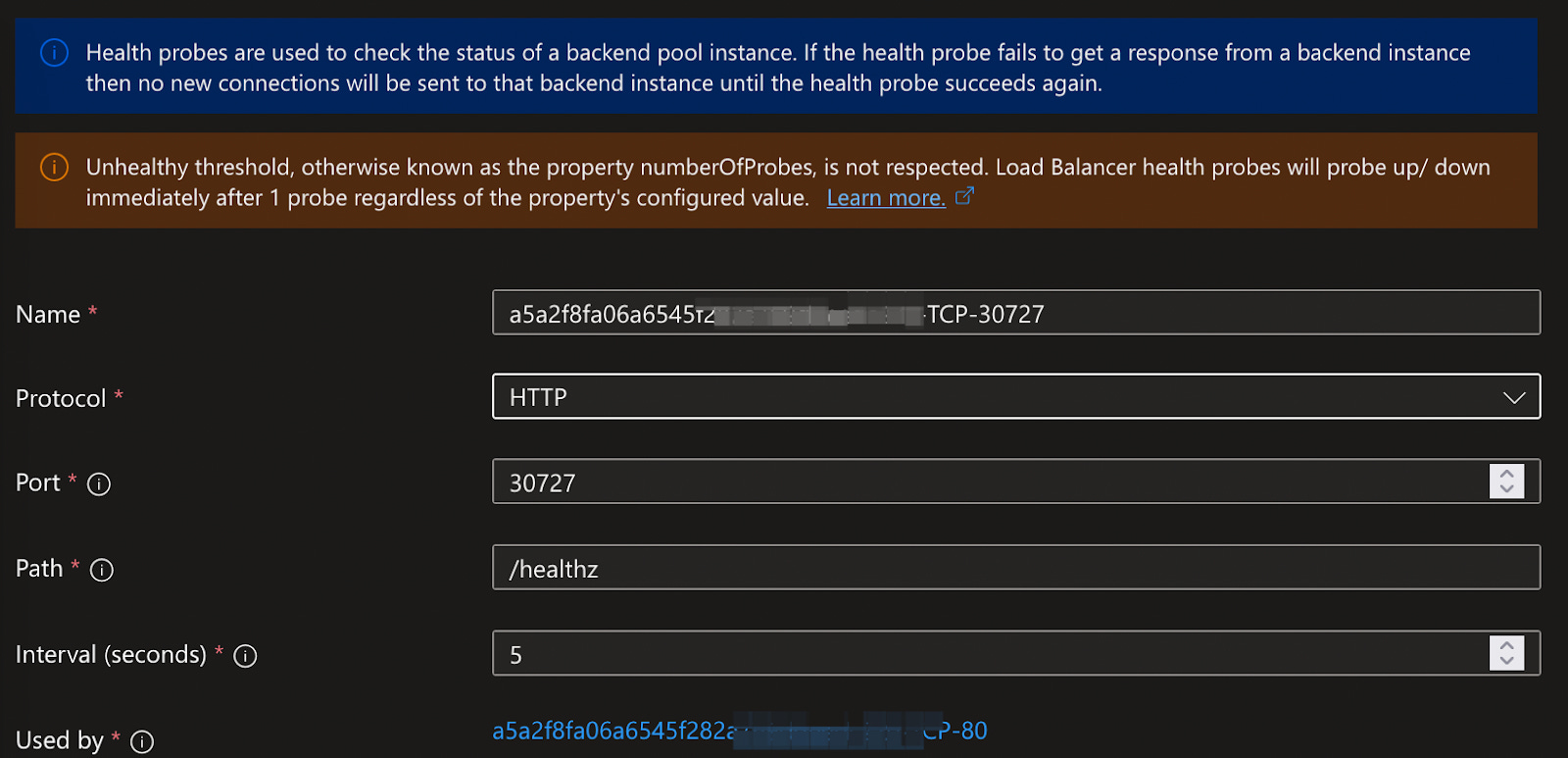
Here's how we configured our Kubernetes service in Local mode:

Most Azure Load Balancer configurations remain unchanged, with one key difference: the health probe switches from TCP to HTTP. Kubernetes manages this transition, ensuring only nodes hosting Istio Ingress Gateway pods pass the health checks. Because the second hop (node to pod) occurs locally in Local mode, latency is also reduced compared to Cluster mode.
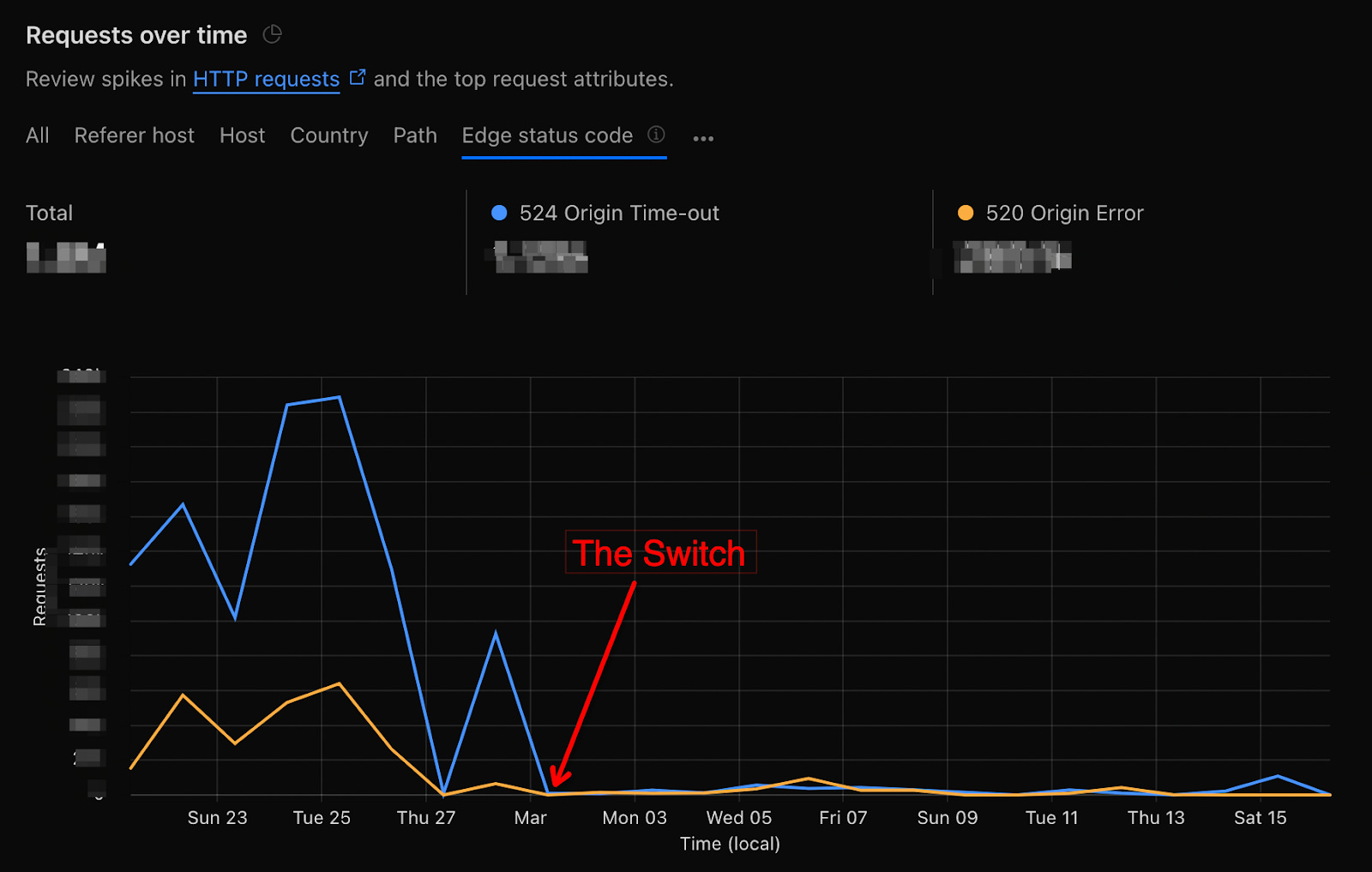
Switching our ingress gateway to Local mode immediately solved our 520/524 error problem, reducing errors to nearly zero. It also had a latency benefit, fewer hops mean less delay in the traffic path.
However, the Local mode comes with trade-offs, also documented by Azure:
Uneven load balancing: Traffic only flows to nodes hosting pods, which might create load hotspots.
Pod scheduling considerations: If your ingress pods relocate frequently, traffic may be temporarily disrupted as Azure’s Load Balancer re-adjusts.
Due to these trade-offs, Local isn't Kubernetes’ default choice. While our adoption of Local mode proved stable, we still consider it a mitigation rather than a complete solution. Ideally, Azure would provide a more robust fix, such as better node eviction handling or configurable backend pools.
Until then, Local mode keeps our traffic stable and helps us sleep better at night.
Summary
We operate several large AKS clusters that experience regular node churn due to the usage of spot instances and our autoscaling policies. During our investigation into persistent but elusive 520/524 errors, we uncovered a fundamental limitation with Azure Load Balancer's default Cluster traffic policy.
The key problems we found:
Insufficient Documentation: Documentation doesn’t clearly warn users about the reliability implications of the default Cluster policy.
Default Mode Pitfalls: AKS defaults to Cluster mode, suitable perhaps for smaller or stable clusters but problematic at scale, especially when spot nodes are present.
Limited Flexibility: AKS currently offers no way to selectively exclude unstable nodes or node pools from the Load Balancer backend pool, limiting our ability to control availability.
Suboptimal Node Termination: AKS does not gracefully deregister terminating nodes from Azure Load Balancer backends, leaving windows of vulnerability during node evictions.
Switching to the Local external traffic policy significantly reduced our ingress availability issues. But Local comes with trade-offs, such as uneven load distribution and increased scheduling complexity. To mitigate this, we use pod anti-affinity rules to ensure even distribution.