

Cloudless Blob: Portable and Cloud Agnostic Blob Storage
Transparently migrating hundreds of buckets across clouds

Written by Frederik Mogensen, member of the storage team who led the development of the Bucket-Gateway infrastructure.
Two years ago, we started a major cloud migration project between two large cloud providers. We migrated our entire microservice stack with hundreds of services, Kubernetes clusters, databases, low level infra, and streaming/batch pipelines in less than a year. And, we did it without downtime or material involvement from product engineering teams.
In this post, we focus on our strategy for migrating hundreds of buckets and petabytes of data across cloud providers. Discover how a cloud-agnostic, portable, and secure blob storage solution made this possible while solving other major problems for us.
Initial design requirements
The main requirements for the cloud migration solution were to be able to move all data from one cloud provider to another, without noticeable disruptions for the clients.
To accomplish this we identified the need for the following three key properties.
A uniform data protocol on top of each cloud provider.
A solution to transparently move data between providers without disrupting data access.
A global authentication and authorization system for all requests, no matter which provider a client tries to access.
The uniform data protocol
We wanted to ensure that our applications would run seamlessly on any cloud provider going forward. This meant that the blob storage protocols used in all our in-house and open source projects could stay the same, no matter the underlying cloud provider. There is currently no shared standard protocol that works on all providers. Each cloud provider has their own blob storage infrastructure with custom APIs, and client libraries for each language with caveats and bugs.
Transparent data portability
The solution must allow for seamless data movement behind the scenes, as seen from the clients point of view. Like a modern cloud-native storage engine, such as CockroachDB where we can define the desired data placement and data moves automatically. Not like running on old-school hard drives where data is stuck when it is written, unless manually copied around.
Security and Audit
Blob storage stores and manages sensitive data for all parts of our business. Therefore our new blob service would need to include a strong authorization and authentication strategy. Leveraging the Spiffe network identities all our applications already get from Istio we can implement a zero-trust blob storage system that works for all cloud providers. No more access key distribution and rotations and no more provider specific service accounts for each microservice.
Finally our new design should also include uniform observability and audit logging for all backing cloud providers. The new blob storage implementation should know when any data was accessed, by applications or developers, as well as be able to generate cost insights down to the single blob level.
Architecting for portability and scalability
To create a cloud-agnostic layer that will work for all applications we decided to implement (most of) the S3 protocol. This protocol is very well documented and supported by most modern applications.
Our new Blob Storage architecture consists of a set of management components, and a new horizontally scalable stateless gateway.
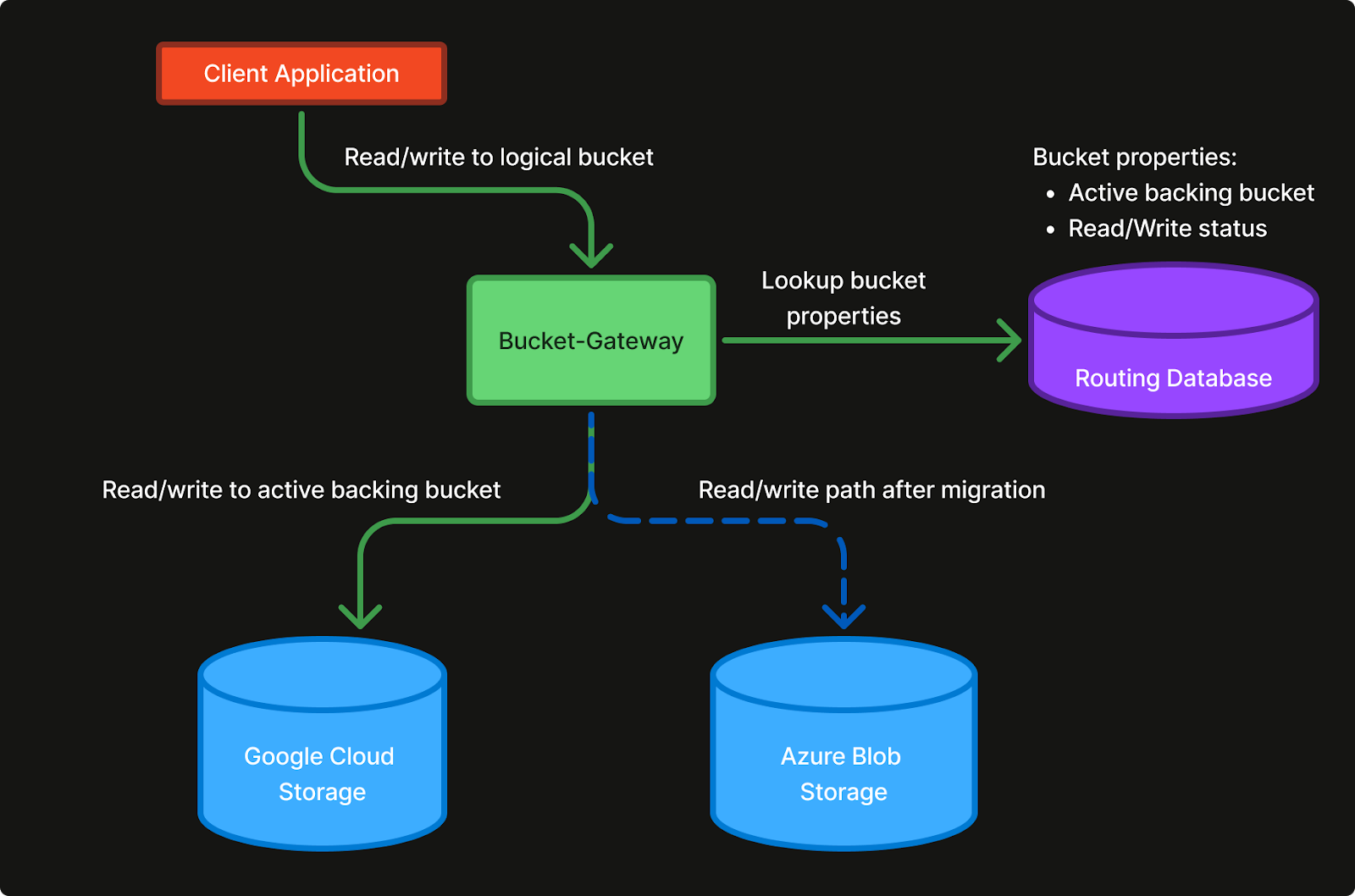
Request flow from Client Application to backing blob bucket
The Bucket-Gateway
The Bucket-Gateway is designed to be S3 compatible and capable of fronting multiple cloud providers, such as Azure Blob Storage, Google Cloud Storage, and Amazon S3. This new component allows us to serve logical buckets that can be routed to actual cloud buckets on different cloud providers. By using the Bucket-Gateway to enforce Authentication (AuthN) and Authorization (AuthZ), it also allows us a single place to control access to our data no matter which cloud provider the data is actually stored on.
Routing
The Bucket-Gateway keeps the complete list of logical buckets (e.g. my-frontend or postgresql-backups), and the mapping for which actual backing cloud buckets to route the requests to (e.g. azure-cloudkitchens-frontend-xyz or gcp-cloudkitchens-pg-backups-123).
This allows us to swap the backing bucket to another region/cloud at any time, without having to re-deploy, re-configure, or even inform our clients and stakeholders. It also removes strict requirements that any bucket name needs to be globally unique which most cloud providers have.
Authentication and Authorization
To allow for easy onboarding of all the client applications we decided to add two different authentication methods. The standard S3 authentication way with Access key ID and Secret Key (Blob Access Keys), as well as a new option of using Spiffe identities from Istio. The Blob Access Keys are used to authenticate any workload or person running outside of our service mesh, as well as for some open source applications that do not allow anonymous authentication in their S3 blob implementations. The Spiffe Identity authentication is used by all applications inside our mesh. Running in the mesh with mTLS enabled between all applications, we have a strong enough security and consistency guarantee from our transport layer that we can remove the signing and checksumming done by the standard Blob Access Keys authentication. This removes a lot of crypto and hashing CPU cycles, as well as allows us to make request handling in a much more streaming fashion.
The Spiffe network identity authentication model allows us to create a zero trust architecture between all client applications and the Bucket-Gateway. Using Spiffe network identities for AuthN removes the need to distribute and rotate keys, as this is already done by Istio. The Bucket-Gateway can use the Spiffe identity from any incoming http request and ask our in-house ABAC-style authorization service if the calling service is allowed to perform the desired S3 action, on the given bucket, for the specific path.
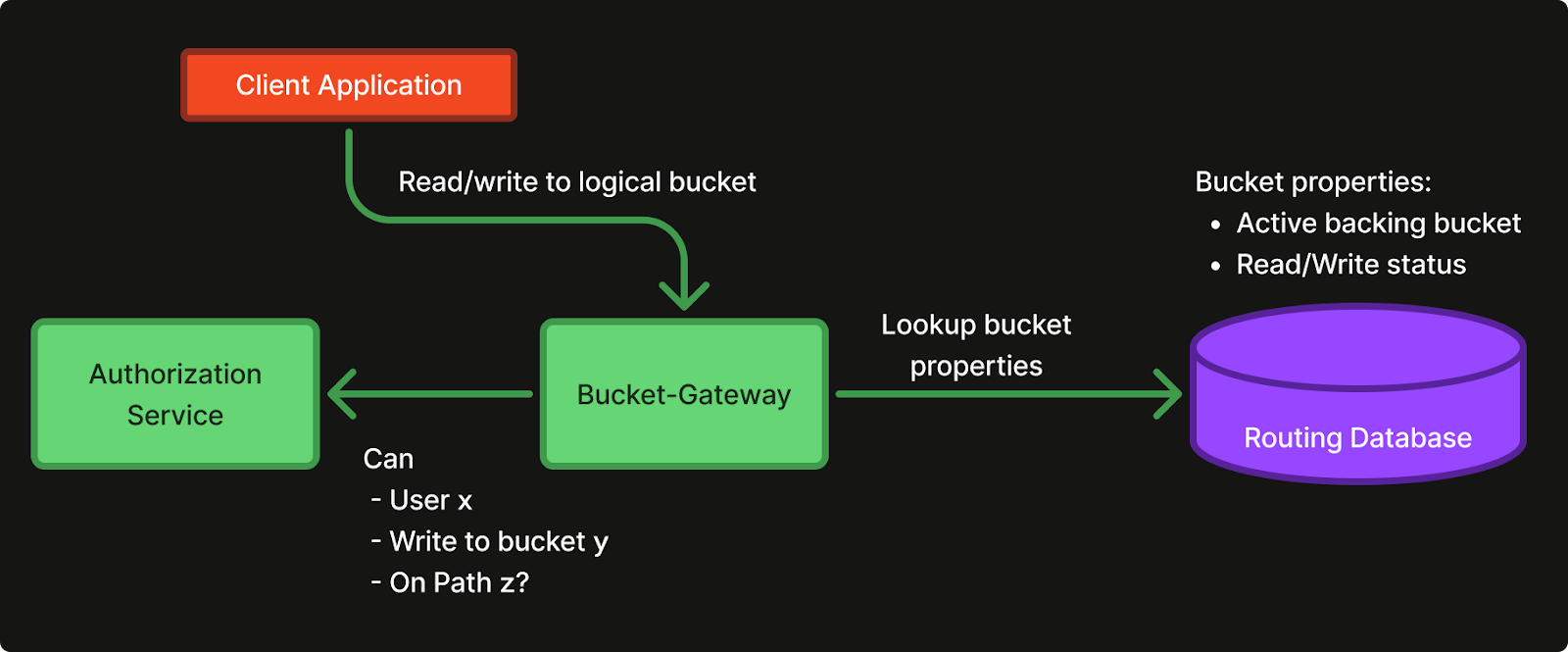
Authorization: The Bucket-Gateway will call the Authorization Service to get an authorization verdict for each incoming request.
Verdicts are cached for a short time, to keep latencies down and guard against DDOS attacks.
# The following is an example of a ABAC style access request
Principal = "postgresql-operator"
Attributes
namespace = "BLOB"
action = "GetObject"
bucket = "postgresql-backups"
object = "myPgCluster/wal/123.tar"Observability
Because the Bucket-Gateway handles all access to blob storage on all our cloud providers, this is a great place to add the required observability. The Bucket-Gateway exposes Prometheus metrics, audit logging, tracing, and all info needed to attribute costs to any client application. Getting request/response logging with the resolution down to a single blob will either be impossible or extremely expensive depending on the cloud provider. With this we can get cost attribution all the way down to a single blob. We know exactly which client read/wrote a given blob, when they did, and how often.
Tradeoffs
Implementing a proxy service like the Bucket-Gateway will of course also introduce certain costs. First, some latency is inevitably added to each data request as it must pass through an extra network jump and a service before reaching the actual cloud provider. We spend a fair amount of time optimizing the Bucket-Gateway by keeping memory allocations low and ensuring that any metadata we need to handle a request is already cached in an up-to-date in-memory cache. Compared to the time spent moving large amounts of data into and out of external storage the extra latencies from the Bucket-Gateway is negligible.
The Bucket-Gateway also introduces an additional point of failure. Apart from rigorous testing, we mitigate this by autoscaling the Bucket-Gateway horizontally across multiple cloud regions, and by isolating heavy data warehouse clients from latency sensitive end-user traffic.
Migration flow
The migration flow consists of moving data and changing the source of truth. For the actual migration we need two extra components.
The Bucket-Migrator
The Bucket-Migrator is responsible for moving the actual data from one backing bucket on any cloud provider, to another backing bucket on any other cloud provider.
It handles initial backfill (Copy) of the new backing bucket by copying all blobs from the source bucket to the sink bucket, as well as synchronizing (Sync) the content of the two backing buckets on demand.
The Bucket-Operator
The Bucket-Operator looks at a desired specification for a bucket and tries to ensure that the real world matches the spec.
For a cloud migration this is done by provisioning a new backing bucket in the right cloud and region, backfilling the new bucket by starting a job in the Bucket-Migrator, and setting up the correct authorization policies for any client on a given bucket.
During the migration from one backing bucket to another the Bucket-Operator is responsible for changing permissions on the logical bucket (setting the bucket as read-only at critical times), triggering copy and sync jobs in the Bucket-Migrator, and updating routing information for the logical bucket. Thereby setting the new bucket as the source of truth.
Copy and Sync
To ensure write-unavailability is kept to an absolute minimum we implemented the following Copy-and-Sync design.
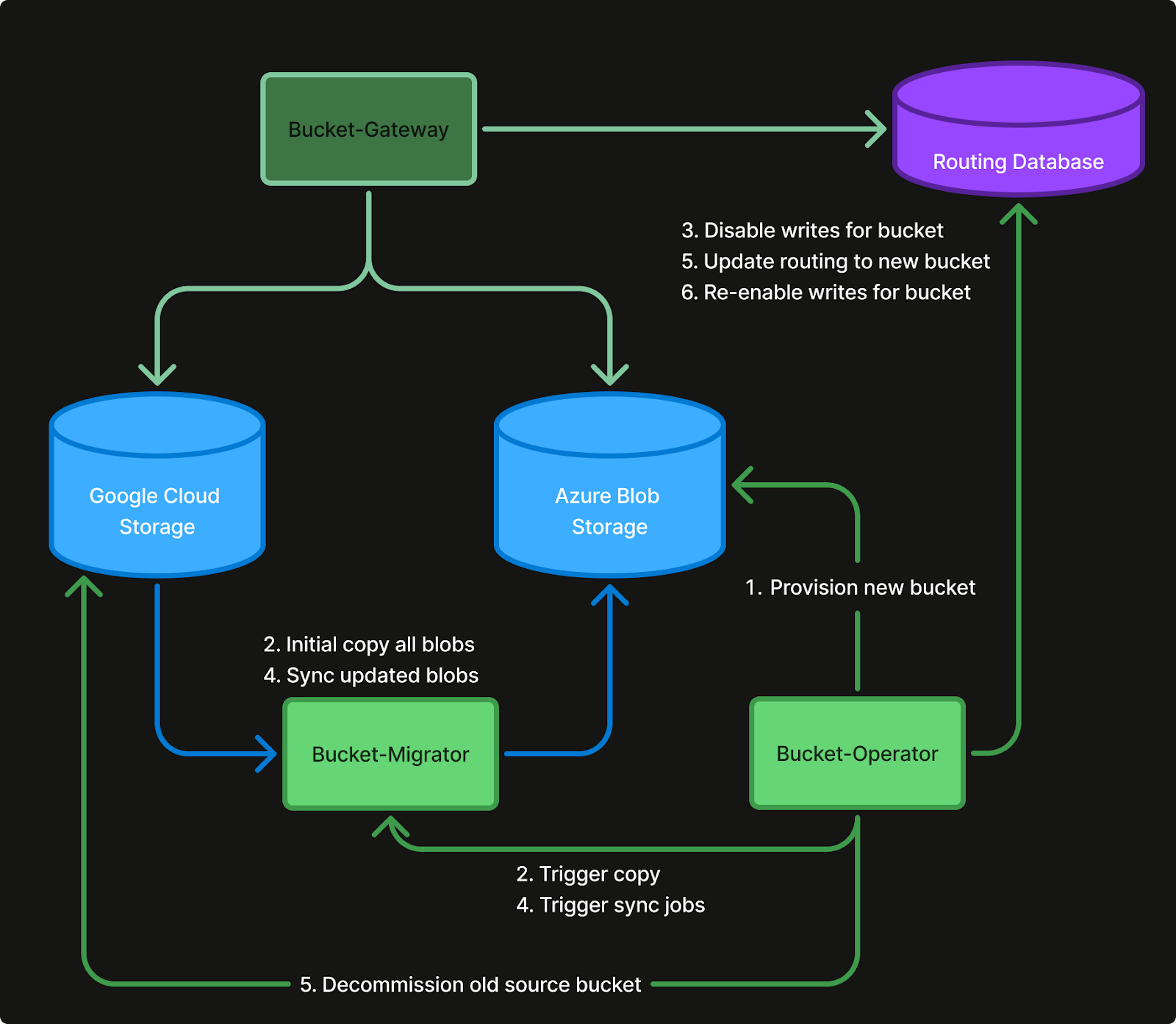
Migration flow: Bucket-Operator manages the permissions on the bucket, and instructs the Bucket-Migrator to copy and sync blobs.
The Copy Phase
The Copy part of the algorithm will make an initial bulk copy of all blobs in the source bucket to the sink. This is performed by listing the source bucket and starting a server-side upload for each blob, by signing a URL for the source bucket and instructing the sink bucket to fetch the blob from the signed-URL. This ensures that we do not have to pull all the data through our Kubernetes clusters and internal network.
The Copy phase does the bulk of the work and the duration of this phase depends on the number of files in the bucket. The phase is completely asynchronous with no impacts on the client workloads, even though it might run for multiple hours or days.
The Sync Phase
The Sync phase of the migration lists all files in the bucket on both source and destination to check whether they are identical. It performs the following series of checks and actions:
Check whether any blobs are missing in the sink
If any blobs are missing in the sink, it uploads them from the source
Checks whether any blobs exists in the sink that are no longer in the source bucket
If any such blobs exist, they are deleted.
Check if the ETag on the sink and source blobs match
If not it re-uploads the new version of the file
Check if the Metadata content matches the sink and source blobs
If not it updates the metadata
The duration of the Sync phase depends on the number of files in the bucket and the amount of changes performed since the one-time copy was started. During this phase the bucket must be read-only to ensure consistency.
The actual migration process consists of the following 6 simple steps:
Provision new backing bucket on destination cloud provider
Initial One-time Copy of all blobs from the Source bucket to the Sink bucket
This part is completely asynchronous and has no impact on the availability of the bucket
Disable writes on the bucket in the Bucket-Gateways
After this the bucket is only read-available.
Sync blobs that has changed or been deleted since the Copy phase
The length of this step is proportional to the number of blobs changed and deleted since the copy phase.
To ensure this step is as fast as possible we plan it for a time of day/week when the given bucket has the least amount of activity.
The sync can also be run multiple times without problems. This means that for high through buckets, we can run the sync once, then disable writes, and then run the sync again. In this case the last sync only needs to handle the blobs updated while running the first sync.
Update the routing information for the logical bucket in the Bucket-Gateways to route all requests to the Sink bucket.
Re-enable writes in the Bucket-Gateway for the logical bucket.
The bucket is now completely migrated and write-available again.
For some clients we were able to completely skip the Sync phase, by pausing client ingestion pipelines, such as Flink and Spark jobs or frontend build pipelines.
The End Result
We created a cloud-agnostic interface and a new Blob Storage architecture with horizontally scalable components, including the Bucket-Gateway, Bucket-Operator, and Bucket-Migrator. The Bucket-Gateway handles S3-compatible requests, routing, authentication, authorization, and observability. The Bucket-Migrator orchestrates data migration using a Copy-and-Sync design, ensuring minimal write unavailability and no read unavailability.
We successfully onboarded all our stakeholders to the new Bucket-Gateway instead of going directly to the cloud provider proprietary APIs. Using the tooling described above we migrated hundreds of buckets with petabytes of data, from multiple regions and environments, to our new home cloud. Most clients experienced only a few seconds or minutes of write unavailability, and no clients experienced read unavailability.
This new architecture also allows us a very interesting set of additional features. The later iterations of the Bucket-Gateway includes
Sharding buckets across Storage Accounts in Azure to remove Azure throughput limits.
Implementing shared in-cluster caches to skip reading the same file multiple times in different services
Multi-region/multi-cloud buckets with replicated data for local reads and disaster recovery/business continuity.
Read more about how we implemented those in the next article Cloudless Blob post.
Cover photo by Carlos Horton.