

Otter Assistant: LLM Support Agent
How to build an LLM support agent that users appreciate

Written by LV Lu (Data Science), Rob Harell (Product), and Brian Attwell.
An exceptional customer support experience is the cornerstone of a lasting customer relationship. This is why we built Otter Assistant, our in-house Gen-AI chatbot that currently handles ~50% of inbound customer requests quickly without human intervention. This post describes our journey over the past year building and scaling Otter Assistant.
About Otter
Otter is a delivery-native restaurant hardware and software suite used to manage restaurant operations and aggregate & derive insights from restaurant data. Each of its product lines has many features, with many integrations. And restaurants want a lot of customizability.

A broad feature set creates customer demand for support. These customers appreciate the speed and reliability that Otter Assistant can deliver over traditional call center agents, as long as we continue to offer the option to contact a 24/7 human agent if preferred.
Build vs Buy
In Q1 2024, we started by analyzing the distribution of customer issues and found that resolving these tickets required deep integration with our systems. For example, a support agent has tightly controlled permission to review a customer’s menu, update their account, or tweak remote printer configuration. At the time, there were no vendors that offered our needed level of integration flexibility without hard coded decision trees, like shown in the image below.

And when we began to experiment, we found that much of the historical value provided by these vendors (Zendesk has great features for configuring workflows through UI, NLP based intent matching, etc) was significantly reduced by LLMs. LLMs reduced the need for this vendor infra, allowing us to largely focus on domain specific problem solving when building our agent.
Bot architecture
The bot system and workflows span an online conversation flow and an offline management flow. The next section covers the primary components of each.

Conversation flow
When we began implementation in Q2 of ‘24, the term “agentic” had yet caught on. However, by setting out to emulate the diagnostic and resolution steps taken by our agents, we naturally followed agentic approach. Concretely, we designed the bot to use function calling and mimic how human support agents work:
Based on customer request, find out the corresponding predefined procedure
If there is one, follow the steps
If not, try to conduct research in knowledge base
When run into issues or can not find information, escalate
To accomplish this, we designed four main types of functions: GetRunbook, API & Widget Functions, Research, and EscalateToHuman, to accomplish each of the essential support tasks above.
GetRunbook function - injects relevant issue resolution steps
After evaluating support issues by volume and resolution complexity, we selected the top high-volume and low-to-medium complexity issues to translate into bot “runbooks”. These runbooks supply instructions on the steps the bot should take to diagnose the user’s issue statement and tie it to a known root cause, and then to either make the necessary API calls to resolve the issue, or surface the corresponding solution “widget” (both of which will be covered below). Conceptually, the runbooks function like a decision tree, but unlike the previous generation of bot tech, can be written in plain text, making them 1) significantly easier to implement and maintain 2) more modular and traversable during runtime diagnosis.
Mechanically, GetRunbook function takes the user issue description as an input and outputs a corresponding runbook if it can find one. Otherwise it returns “Not Found”. Under the hood, we use a LLM for intent matching and runbook retrieval. Based on the embedding of user issue description, retrieve relevant runbooks from our runbook repository (vector db) based on semantic similarity [Ref], then issue a separate LLM call to let LLM pick the correct one from the candidates and return not found if there is no good match.

If there’s a match, the LLM then begins to work through the listed runbook steps, gathering follow-up information from the user and/or executing API calls as needed until it reaches the end.
API call functions - retrieves customer data for diagnosis
As the bot works through a runbook, it has the ability to choose from a list of API wrapper function calls to gather information (e.g. fetch store status status) and/or modify a user’s account. Fortunately, we were able to largely reuse pre-existing API calls within the Otter ecosystem.
Critically, to avoid leaking user data to those that shouldn’t have access, for any internal APIs, we call backend APIs with the user token passed over as part of each Otter Assistant service request. This way, we maintain and reuse existing permission control models and auth infrastructure.
Widget functions - performs action with user confirmation
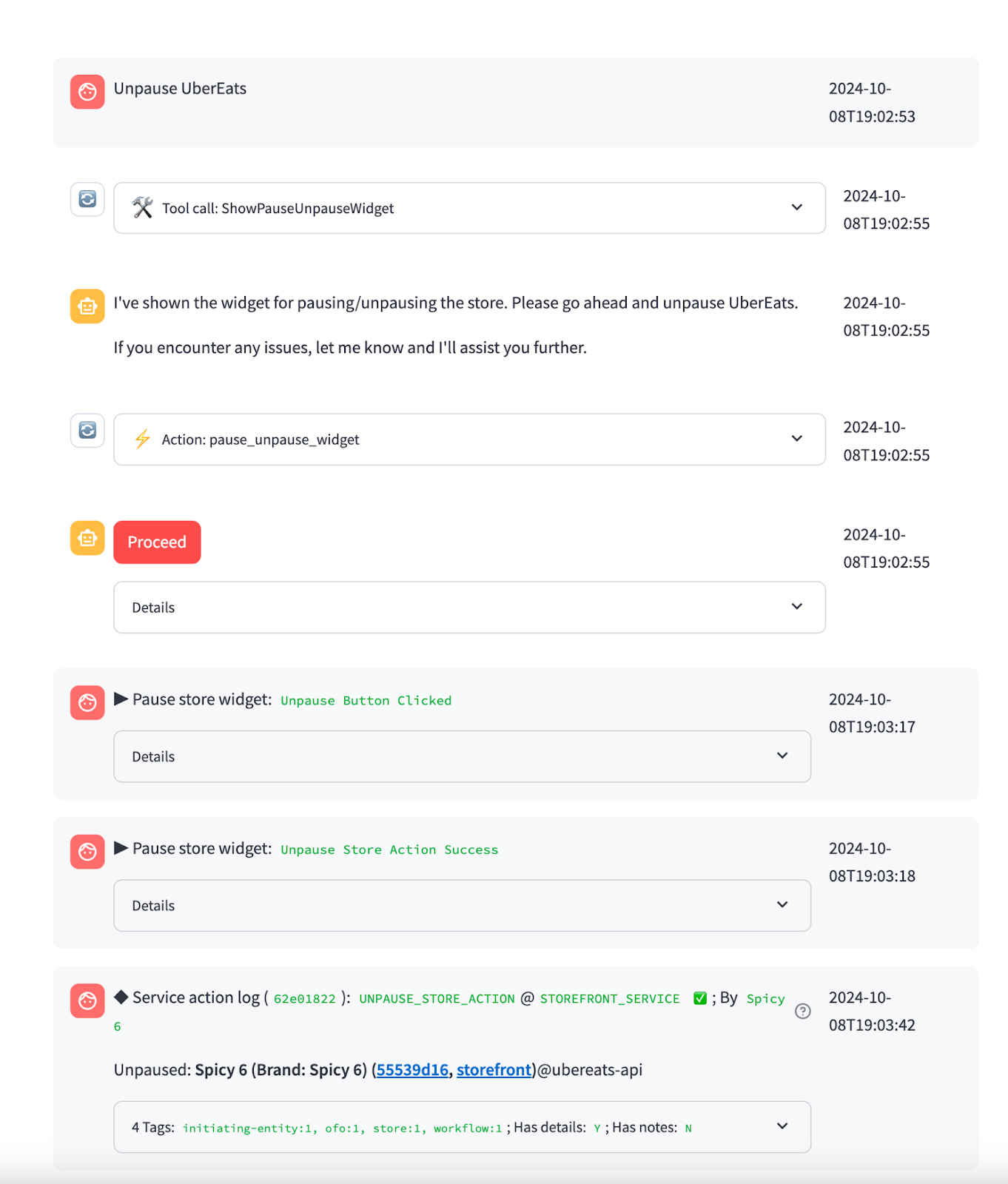
After the bot has identified the root cause, it then takes the appropriate action to address the issue. With exception of simple account modifications, we present most write operations within “widgets”, or embedded UI modules. For example, customers requesting to pause their store are presented with the following widget:

Widgets provide the following benefits:
Encapsulation/reuse
Distributed ownership
Information density
Easy for user to confirm & eliminates risk of hallucination
When the bot decides it’s appropriate to surface a widget, it calls the corresponding widget function (informing the LLM that a widget is being displayed) and simultaneously emits a notification to the external chat UI. The chat UI then renders the widget UI within the message.
For any critical write operation (e.g. Pause store, update price) we require user review and explicit click confirmation before kicking off the operation. We strictly follow this approach to mitigate risk from LLM hallucination (e.g. incorrectly assume that the user wants to pause a store). This approach also provides users a quick way to modify inputs for the write operation if the LLM got details wrong.
Research function - finds answers in knowledge base
The research function is designed to retrieve and summarize helpful answers to user questions that don’t match a runbook. We designed the research function to mimic how humans find answers online in our help articles: conduct a search with a question, then read through top search results to come up with final answers.
To implement this flow, we first convert the help articles in Otter’s knowledge base to embeddings using an LLM offline and store them in a vector db. Then, when we receive a request, we convert the user question to embeddings to retrieve the top relevant articles from vector db based on semantic similarity. Next, we issue a LLM request to each top article to find relevant answers to the user’s question. The process stops when either it has found n answers or gone through m results (both configurable parameters). We lastly issue a separate LLM call to combine the answers into a final answer to return as the function response.

EscalateToHuman function - hands off to human agent
This function provides LLM the capability to inform us the conversation should be escalated to a human agent. When the LLM detects a user’s intent to escalate, we can inform the chat message interface to pass conversation control to the assigned human agent, which in turn calls Zendesk to connect to a live agent.
Bot management
The aforementioned components cover Otter Assistant’s core conversational capabilities. However, like with any software, robust testing and management processes are needed to ensure the bot works at scale. Unlike with traditional software, however, the inherent randomness and unpredictability in the LLM-powered conversational flow called for a bespoke set of tools to serve this need:
Local development and playground
Bot validation testing
Bot conversation review & analytics
Local development and playground
Given the stochastic nature of LLMs and multi-modal nature of Otter Assistant conversations (which encompass both text and bot actions/widgets), developers require a chat simulator for effective debugging. To facilitate this, we developed a Streamlit-based library. This library allows developers to interact with the bot through a web UI, displaying input and output arguments for each function call to ensure the bot's end-to-end flow is correct.
Bot validation testing
After confirming new capabilities work in the development environment, we pass the bot through a round of validation testing. Given the randomness inherent in LLM systems, it often requires multiple iterations of conversation to expose & verify specific bot behaviors, which is time consuming if done manually. Moreover, changing prompt logic in one place could cause unanticipated behavior changes elsewhere that could be difficult to detect. These challenges surpass traditional software testing frameworks, which rely on 100% deterministic execution and structured output.
Therefore, we developed a new test and evaluation framework for Otter Assistant and any other chatbot, which involves:
Predefine a set of test scenarios, e.g. customer’s store is paused
For each test scenario we also define a list of expected behaviors, e.g. confirm which store, check status, then launch widget
Launch a chatbot using LLM to play as customer to chat with our bot
Leverage LLM as a judge to assert on expected behaviors based on conversation transcript between the bot and customer

With the above framework, we can evaluate chatbots through a mechanism that is similar to traditional unit tests, where we define a set of inputs and assert on expected output for each.
Bot conversation review & analytics
Once the bot has been validated, it can be deployed with a reasonable degree of certainty that it will behave as expected. But then comes the question: how is it performing? To answer this, we defined and instrumented a “resolution” metric. This metric informs us of the Bot’s overall performance and in turn the business impact it generates, and allows us to identify issues and improvement opportunities.
Bot issue analysis presents challenges compared to error identification and resolution in traditional software development. Concretely bots can err many ways at the software layer and the model layer, and it’s impossible to know which without manual inspection. To streamline this conversation review process, we built a conversation inspector tool in Streamlit that allows reviewers to load each past conversation and visualize the chat history and action logs similarly to the local testing app:

This tool is available to both Otter developers and non-developers, which has helped scale our efforts to investigate issues and suggest improvements.
Lessons from running a bot initiative
When we began implementing Otter Assistant last year, there were no established bot guidelines or frameworks. Though frameworks have begun to emerge (e.g. OpenAI’s Agents SDK), and as solution providers continue to enhance their offerings, we still feel building in house has proved to be the right decision. Other organizations should weigh their build-vs-buy according to their abilities and the degree of control and customization they foresee requiring for their use cases.
Beyond build-v-buy, the most important takeaway from the development and launch of Otter Assistant has been the importance of defensible, actionable success metrics to the overall project’s success. These metrics have proved instrumental in persuading ourselves of the Bot’s value to Otter and users and establishing a feedback loop to improve the bot over time.
Lastly, Otter Assistant (specifically, the high fidelity conversational feedback generated by Otter Assistant) has exposed multiple product and platform issues previously lurking undetected in Otter systems. We’ve thus incorporated bot-derived feedback into our product strategy alongside traditional sources such as user interviews and competitive analysis.
Next steps
After close to one year of development, Otter Assistant solves ~half of support requests autonomously without compromising customer satisfaction. In future blogs, we will share more about our lessons learned around prompt engineering, as well as best practices we found for how to design and structure functions.
While it is great to see existing LLMs frameworks already starting to deliver value to our customers and unlocking use cases that weren't possible before, in certain scenarios, we have started to hit limitations on how much we can improve without more fundamental improvements on the LLMs. Therefore we are exploring how to establish a more efficient feedback loop mechanism so the bot can self-sufficiently become smarter over time.
Looking ahead, we think this is just the beginning of a new era for product design and development. At CSS, we believe agentic chatbots can hugely elevate customer experience. Handling customer support requests is just a starting point!
Appendix: Q1 2024 Vendor Comparison
After categorizing support tickets, we identified the following key requirements for our chatbot.
LLM-native: no reliance on hard-coded decision trees to define Bot logic
Ability to choose the underlying model(s) and control prompt text
Ability to update user accounts (stores, menus, orders, printers, etc) via API function calls, while maintaining adherence to Otter’s access controls and permissions as a guardrail on the above
Ability to seamlessly escalate from bot to human within a single chat window
With these key requirements in mind, we conducted an evaluation of third party solutions while simultaneously developing an internal prototype Q&A bot that performed RAG on our existing support knowledge base. Below was our comparison.

Established vendors' products primarily featured hard-coded decision trees and were still working to determine their LLM product strategy. On the other end of the spectrum, we spoke with several startups building LLM-native chatbots for support, but didn’t encounter one we believed would be able to manage the complexity of resolution steps required for our top issues. We thus decided to build our own in-house Bot back end while leveraging Zendesk’s Sunco Web SDK front end (to minimize time to market; we have since replaced it with our own custom front end) as our MVP solution.